We at Arroyo Labs like Angular; That is a very fortunate fact because it plays a huge role in our daily tasks for 4+ years. However, during those 4 years, a lot has changed in the landscape of web-development and we always try our best to refresh and reinvent ourselves.
VueJS has been a welcome addition to the mainstream web-development scene and we were extremely happy to jump into it as soon as we could. After completing a project with VueJS, here is some of my take away after heavily using Angular.
Of course, this blog post is subjective to my own experiences and may differ to others. You and I may have our agreements and disagreements but I say that is part of the fun. That being said, here I go!
Right off the bat I enjoyed VueJS for the same reason I enjoy Angular because both framework are supported by the official development team instead of solely depending on the 3rd party development community. While there are great 3rd party alternatives of NPM libraries available to augment both framework, the feeling of comfort in standardization and a strong guarantee of compatibility coming from the official dev-team is nice to have.
For our recent project, we used Vue Cli to generate a simple Vue environment with the router feature for single page application to get started. Due to the timeframe of the project, unit tests were not included in the webpack.
Creating Components
The two framework share many characteristics that acclimating to Vue took almost no time at all.
Angular-CLI provides ‘ng g c component-name’ to generate new component. It generates the component’s html, css, ts (typescript) file and automatically registers the component in the app.module.ts file. Only the html and ts files are being used as we have ditched the component specific CSS file for SASS. The moment you include the component’s selector such as <app-compoment-name></app-compoment-name> the implementation of the component is complete.
At the time of this writing, VueJS doesn’t have the CLI command to automatically generate the component file. Although the component file has to be created manually, I found that much of the tedious task can be skipped after a brief research.
First, manually create a single file component file inside the /src directory. If you are a VSCode user, a plugin called Vetur helps alleviate you from setting up the <style>, <script>, and <template> structure with the magic word: scaffold. If you are a front-end developer but not a VSCode + Vetur user, please go and install the IDE and plug-in because I think you’re a great person and you owe it to yourself the best things in life.
Behold the scaffolding!
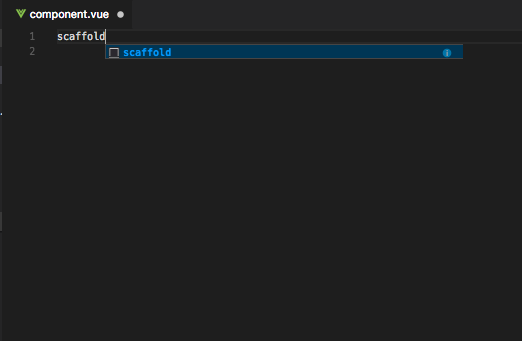
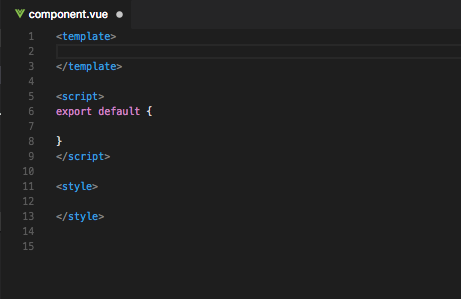
After typing “scaffold”, the skeleton of component is autogenerated.
(And yes, my jaws did drop with a slight gasp at this discovery to others’ amusement).
Similar to Angular, the newly created Vue component must be registered in the App.vue file and implemented by using the component selector.
The difference in Components
There are few routine tasks that I go through when starting with a new Angular component:
– Check dependency injection for required lifecycle hooks and services
– Declare required local data and make reference to imported services inside the constructor
– Determine the best lifecycle hook to use with the component
– Assign initial value to the local data
– Create methods for component inside the scope of the constructor
During these routine, I have noticed that a lot of times were spent jumping back and forth between html, ts and scss files.
The usual routine task for Vue component would be:
– Use the scaffold
– Import scss files inside the <style> tag
– Determine the best lifecycle hook to use with the component
– Define the export default structure inside the <script> with data(), methods, computed, etc.
Because of the single file component, there were less of jumping back and forth between multiple files. However, because I have opted for external scss, back and forth between vue and scss files were unavoidable.
Coming from Angular to Vue, writing Javascript in the component felt rigid and organized which is why I think Vuejs is a very beginner friendly. The local variables, methods, data watcher (to my pleasant surprise), and etc are explicitly compartmentalized to my joy. But at same time, I also felt small disappointment that Angular doesn’t enforce the same rigid organization because our largest Angular component contains 20+ functions that can benefit highly from it.
Conclusion
Getting to know Vuejs after finishing our first project was a joy. After working with Angular for a very long time, Vuejs provided me with a familiar and yet refreshing take on modern framework. To summarize, although the Vue’s CLI doesn’t alleviate me from manual tasks that Angular’s CLI automated, I enjoyed the lightweight feeling that Vue’s component provided, its rigid structure, and (to my pleasant surprise) a simple and intuitive implementation of watch function to deal with asynchronous functions easier. As someone who deals with the complexities of asynchronous functions from time to time, Vue component’s watch feature sets itself apart from Angular for me. Vue, it’s been a pleasure working with you and I hope to bump into you near future.
