I remember when I was learning Promises. The first thought coming through my head was “wow, this is the next step” mainly because it had me stop to think differently on everything I have learned so far. The shift of paradigm from reading synchronous to asynchronous code was little overwhelming.
Of course, this was when I graduated from Procedural Code University with a major in Callback hell. Luckily for me, I was able to grasp the concept of promises/callbacks, gained appreciation for it, and programming was fun again.
The reason for my reminiscing is because Javascript’s ES7 introduced the Async/Await which became my new favorite feature.
To specify further, below is a short example of Promise that fetches a random Ron Swanson quote from an API. In this example, we fetch a random Ron Swanson quote, JSONify the response and console log them through chains of Promises.
function getRonSwansonQuote() {
const url = `https://ron-swanson-quotes.herokuapp.com/v2/quotes`;
fetch(url)
.then(response => response.json())
.then(data => console.log(`${data[0]} - Ron Swanson`));
}
getRonSwansonQuote(); And the following is the code example of Async/Await that does the same thing as above.
async function getRonSwansonQuote2() {
const url = `https://ron-swanson-quotes.herokuapp.com/v2/quotes`;
const response = await fetch(url);
const data = await response.json();
console.log(`${data[0]} - Ron Swanson`);
}
getRonSwansonQuote2();Do you have a preference between the two code examples above? It wouldn’t be much of a blogpost if I didn’t say I personally prefer the Async/Await method. It rids of callback functions and its learning curve and replaces them with what reads more synchronously.
So how does Async/Await work?
Whenever the keyword ‘async’ is placed before function declaration, it allows the word ‘await’ to be placed in its scope right before a promise returning function. ‘Await’ pauses the function until the promise is resolved. The resolved value is then stored in the variable it is set to.
In the Ron Swanson function, ‘async’ is placed before ‘function getRonswansonQuote2()’. The ‘await’ is placed in front of the fetch and jsonify. In this case, the getRonSwansonQuote2() awaits until HTTP request fetches the response from the API and then awaits once again for the response to be JSONified.
Now that the basics of Async and Await are covered, let’s ramp up the complexity a little for the next example.
In this code, we have a function that makes http requests to the following:
The function below makes an http request to ‘aww’ subreddit. Once the ‘aww’ request is finished, the awaiting ‘animalsbeingbros’ request is made. In another words, the two http requests are being made sequentially. Once we receive both responses, they are output to the console.
async function reddit(sub) {
const url = `https://api.reddit.com/r/${sub}`;
const response = await fetch(url);
return await response.json();
}
async function getImageUrlSequent() {
//sequential http requests.
//2nd http request isn't made until 1st is resolved
const aww = await reddit('aww'); //returns promise
console.log('await aww completed');
const animalsBros = await reddit('animalsbeingbros'); //returns promise
console.log('await animalsBros completed')
//console log happens when both http requests are finalized
console.log(aww);
console.log(animalsBros);
}
Of course, each http request and return is almost instantaneous so there are no visible setbacks. But what if you find yourself having to make requests to fetch a large amount of data? It would be difficult to wait for one time consuming http request after another. It would be a performance nightmare.
To mitigate that, here is the code that runs the same two http requests concurrently as opposed to sequentially.
async function reddit(sub) {
const url = `https://api.reddit.com/r/${sub}`;
const response = await fetch(url);
return await response.json();
}
async function getImageUrlConcurrent() {
//two concurrently running http requests.
const awwPromise = reddit('aww'); //returns promise
const animalsBrosPromise = reddit('animalsbeingbros'); //returns promise
const aww = await awwPromise;
const animalsBros = await animalsBrosPromise;
console.log('aww', aww);
console.log('bros', animalsBros);
}
The difference between the sequential and concurrent method is, for better or worse, subtle.
Instead of firing the http requests sequentially, we make sure that they both fire at the same time with the following snippet.
const awwPromise = reddit('aww'); //returns promise
const animalsBrosPromise = reddit('animalsbeingbros'); //returns promise
We place the ‘await’ keyword before the promise variable which places the function execution on hold until both of them gets resolved. Once the slower of the two process is finished, the values are output to console.
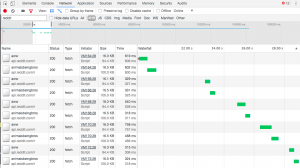
Out of pure interest, we can observe the subsequential vs concurrency function in the chrome developer tool.
In the screenshot below, you can see the subsequential function in action. At the run-time of the compiler, you can see in the Waterfall section that ‘aww’ is fired followed by ‘animalsbeingbros’.
Unsurprisingly, this is how the concurrent function looks like.
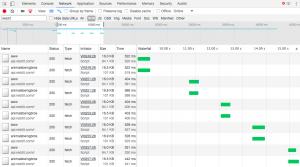
How do these two compare in terms of performance? For the sake of doing, I ran the compiler for each function 5 times and averaged its performances.
| Sequential | Concurrent | |
| 1st | 1221 ms | 522 ms |
| 2nd | 660 ms | 404 ms |
| 3rd | 858 ms | 404 ms |
| 4th | 1226 ms | 528 ms |
| 5th | 639 ms | 442 ms |
| Average | 920.8 ms | 460 ms |
*For sequential process, the sum of both ‘aww’ and ‘animalsbeingbros’ were used to calculate the average.
*For concurrent process, the performance of the slowest request was used to calculate the average.
Turns out, the concurrent code is twice as efficient as sequential code. Not too shabby 🙂
That’s it for this blog! I hope you found reading this enjoyable. I certainly enjoyed writing it.
Until next time!
